Key Insights
Optimizing TensorRT-LLM focuses on enhancing the performance of large language models by leveraging TensorRT for efficient model serving. Best practices involve optimizing models for faster inference, reducing latency, and ensuring scalability across diverse deployment environments. By fine-tuning model architecture, leveraging quantization techniques, and utilizing TensorRT's capabilities, organizations can achieve real-time AI inference on edge devices and private cloud infrastructure.

Large Language Models (LLMS) are transforming how businesses operate across sectors, including customer service, software engineering, data analytics, and healthcare. While LLMs unlock unprecedented capabilities, deploying them at scale introduces significant challenges. These include inference latency, high GPU and memory usage, scalability bottlenecks, and elevated operational costs. NVIDIA’s Tensorrt-LLM provides an answer, offering a dedicated inference optimisation toolkit designed to maximise LLM performance using hardware acceleration and fine-tuned software configurations.
This blog provides a comprehensive guide to tuning Tensorrt-LLM for optimal model serving. It targets computer science and AI students, data engineers, and machine learning practitioners exploring the intricacies of large-scale LLM deployment in production environments.
What is TensorRT-LLM?
 Figure 1: TensorRT-LLM Optimization
Figure 1: TensorRT-LLM OptimizationTensorrt-LLM is an open-source, high-performance inference library from NVIDIA that optimises large language models. It is built upon NVIDIA’s Tensorrt deep learning inference SDK and leverages custom CUDA kernels, allowing it to run state-of-the-art models with extreme efficiency on NVIDIA GPUS. Supported models include GPT-3, LLaMA, Mistral, Falcon, and others, with seamless integration into serving solutions like Triton Inference Server.
Core Features:
-
Transformer Kernel Fusion combines key transformer operations— such as LayerNorm, matrix multiplications, and bias additions—into a single kernel for efficient execution.
-
Low-Precision Inference Support (FP8, INT8, BF16): Enables rapid computation with minimal accuracy trade-offs.
-
Advanced Parallelism: Employs tensor, pipeline, and sequence parallelism to distribute workloads across multiple GPUS.
-
Prompt and Key-Value (KV) Caching: Prevents redundant computations by reusing attention mechanisms.
-
Triton Inference Server Compatibility: Simplifies deployment through integration with production-ready inference solutions.

Why Optimisation Matters in LLM Inference
Deploying LLMS without performance optimisation can result in serious issues:
-
High Latency: Delays in model response times hinder user experiences, especially in real-time systems.
-
Inefficient GPU Utilisation: Valuable hardware resources may remain underused.
-
Limited Scalability: Challenges arise when extending workloads across multi-GPU or multi-node clusters.
-
Operational Cost Overhead: Non-optimised systems drive up GPU hours, energy consumption, and memory usage.
Through Tensorrt-LLM, developers can achieve:
-
Up to 4x improvement in throughput compared to native PyTorch.
-
Per-token latency reduced to under 10 milliseconds.
-
Greater cost-efficiency by maximising GPU use.
-
Reliable multi-user concurrency for enterprise-scale deployments.
Best Practices for Tensorrt-LLM Optimisation
To get the most out of TensorRT-LLM in real-world applications, adhere to these foundational best practices:
-
Profile First: Always benchmark your inference setup to identify bottlenecks before applying changes.
-
Choose the Right Precision: Based on your hardware and accuracy requirements, select between FP8, INT8, or BF16.
-
Use Kernel Fusion: Reduce execution time by fusing supported transformer operations into a single CUDA kernel.
-
Enable KV Caching: Ideal for chatbots and applications with recurrent prompts.
-
Parallelise Thoughtfully: Apply pipeline and tensor parallelism based on model size and input sequence length.
-
Tune for Concurrency: Use CUDA Graphs, stream concurrency, and dynamic batching to maximise throughput.
-
Deploy via Triton: Take advantage of Triton Inference Server’s scalability, interface support, and resource control.
-
Monitor Continuously: Employ tools like DCGM, Prometheus, and TensorRT Profiler to keep track of performance metrics.
These principles help ensure stability, responsiveness, and efficient use of computing resources in high-demand AI systems.
Best Practices for Tuning Tensorrt-LLM
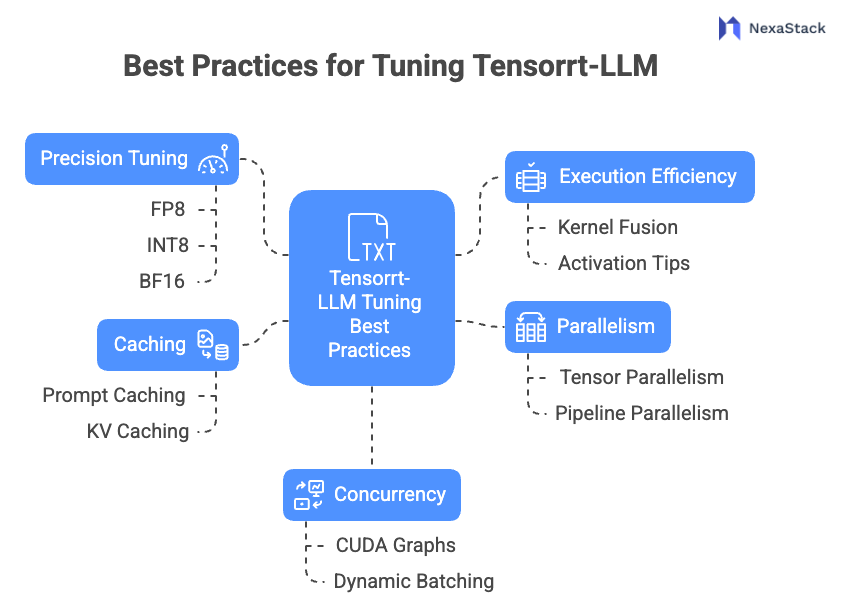 Figure 2: Best Practices for Tensorrt-LLM
Figure 2: Best Practices for Tensorrt-LLM1. Precision Tuning: FP8, INT8, BF16
Why It Matters:
Reducing precision decreases computational load and memory bandwidth without heavily compromising output quality.
Available Modes:
-
FP8: Optimised for H100 GPUS; supports high throughput.
-
INT8: Requires calibration but delivers significant speedups.
-
BF16: A good compromise between speed and numerical stability.
Steps to Implement:
-
Use utilities like
quantize.pyto convert models. -
Calibrate with real or simulated workloads to maintain performance.
-
Tune your precision level based on hardware architecture and application sensitivity.
Expected Gains:
-
FP8 on Hopper architecture offers 2.5x–3x improvements in inference speed.
-
INT8 is ideal for applications with repetitive prompt structures, such as chatbots.
2. Execution Efficiency via Kernel Fusion
What It Is:
Kernel fusion consolidates multiple tensor operations into a single CUDA kernel, reducing memory transfers, synchronisation barriers, and kernel launch overheads.
Commonly Fused Components:
-
LayerNorm
-
Attention Heads
-
Activation functions (e.g., GELU)
Activation Tips:
-
Set
use_fused_attention=trueIn your configuration. -
Compile your engine using Tensorrt-LLM custom ops with flags supporting fusion.
Key Benefits:
-
Shortened compute paths.
-
Reduced memory latency.
-
Improved overall throughput and smoother GPU pipeline execution.
3. Harnessing Parallelism: Tensor and Pipeline Modes
Tensor Parallelism:
Breaks large-scale matrix multiplications across multiple GPUS. Useful when working with models with dense computational layers and shorter input sequences.
Pipeline Parallelism:
Splits model layers across GPUS in sequence. This benefits intensive models and scenarios involving lengthy inputs, such as document summarisation or translation.
Configuration:
-
Modify
tp_sizeandpp_sizeparameters to define the extent of parallelism. -
Use Triton Inference Server’s device mapping and scheduling utilities.
Optimisation Tips:
-
Monitor for imbalanced workloads between GPUS.
-
Tune inter-device bandwidth and reduce communication overhead with NCCL.
-
Consider hybrid setups with both pipeline and tensor strategies.
4. Accelerating Inference with Prompt and KV Caching
What It Does:
Stores the key and value vectors from attention layers, avoiding recomputation across sequential requests or static prompts.
Where to Apply:
-
Multi-turn conversational agents.
-
Retrieval-augmented generation (RAG) pipelines.
-
Applications reusing prompts with different input suffixes.
Activation and Tuning:
-
Enable caching by setting
enable_kv_cache=True. -
Allocate memory buffers according to
max_input_lenandmax_output_len.
Measurable Benefits:
-
Significant latency reduction in session-based applications.
-
More stable throughput under bursty workloads.
5. Optimising Stream and Thread Concurrency
What It Means:
Maximising GPU usage by managing concurrent execution streams and thread-level parallelism.
Best Practices:
-
Adjust
num_streamsbased on available GPU Streaming Multiprocessors (SMs). -
Enable CUDA Graphs to eliminate launch overheads in static input scenarios.
-
Configure Triton’s dynamic batching to merge simultaneous requests efficiently.
Impact:
-
Dramatic improvements in real-time inference for chatbots, recommendation engines, and online search.
-
High GPU utilisation even under unpredictable request patterns.

Efficient Model Serving with Triton Inference Server
Triton provides a robust and flexible platform for LLM serving. Its architecture supports multi-model inference, concurrent requests, and efficient resource usage.
Highlights:
-
Offers HTTP/REST and gRPC interfaces.
-
Manages multiple versions of the same model.
-
Handles complex batching, instance grouping, and memory pinning.
Deployment Workflow:
-
Convert model weights into optimised Tensorrt engines.
-
Organise models into Triton’s expected repository format.
-
Define model behaviour
config.pbtxt, including I/O types and dynamic batching. -
Start Triton with optimised threading, shared memory, and load balancing.
Pro Tips:
-
Use sequence batching for dialogue-based apps.
-
Leverage shared memory to minimise I/O latency.
-
Monitor queue delays and adjust.
max_queue_delay_microseconds.
Monitoring and Benchmarking Inference Performance
Performance monitoring ensures that optimisation is effective and sustainable.
Metrics to Track:
-
Token latency and end-to-end request latency.
-
Throughput in tokens/sec or requests/sec.
-
GPU metrics: utilisation, thermal limits, memory, and power draw.
Recommended Tools:
-
NVIDIA DCGM: Real-time GPU performance telemetry.
-
Prometheus + Grafana: Custom dashboards and alerting.
-
Tensorrt Profiler: Detailed breakdown of every CUDA kernel executed.
Benchmarking:
Use the trtllm-benchmark CLI to:
-
Emulate diverse workloads.
-
Run batch tests on different sequence lengths.
-
Measure average and tail latencies (99th percentile).
Advanced Optimisation Techniques
CUDA Graphs:
Record a graph of kernel executions and reuse it across iterations. Eliminates scheduling overheads, especially useful for repetitive workloads.
FlashAttention v2:
Implements memory-efficient attention computation. Excellent for tasks involving long contexts or input documents.
Rotary Positional Embedding Fusion:
Speeds up positional encoding in models like LLaMA and Mistral.
Speculative Decoding:
Speeds up text generation by combining a fast ‘draft’ model with a slower ‘refiner’ model to verify outputs.

Use Cases and Real-World Applications
Conversational AI:
Chatbots leverage KV caching and CUDA Graphs to reduce latency, maintaining sub-15ms interactions.
Semantic Search and Retrieval:
LLMS powers contextual search engines. Combined with batch inference and quantisation, they become cost-efficient and scalable.
Embedded and Edge AI:
Quantised lightweight LLMS can run inference on resource-limited devices like NVIDIA Jetson, expanding AI capabilities to the edge.
Deploying LLMs in production demands more than model accuracy. It requires thoughtful engineering to achieve high performance, scalability, and cost-effectiveness. Tensorrt-LLM provides a robust framework to optimise each aspect of the inference stack: precision, execution pipelines, memory efficiency, and deployment workflows.
By following these best practices:
-
Engineers can unlock maximum performance from NVIDIA GPUS.
-
Enterprises can scale AI systems with predictable costs.
-
Teams can deliver real-time user experiences powered by state-of-the-art language models.
As LLM adoption grows across industries, mastering inference optimisation with Tensorrt-LLM will be an invaluable skill for modern AI professionals.

