Key Insights
Deploying Jamba 1.5 Mini with NexaStack enables a fast, efficient, and secure AI model serving on private or hybrid cloud. NexaStack’s managed LLMOps streamline deployment, scaling, and GPU optimization—making it ideal for enterprise-grade generative AI with minimal overhead.

As AI revolutionises industries worldwide, the need for efficient, scalable, and secure deployment platforms has never been greater. Whether it’s conversational AI, document summarization, or financial analysis, the ability to deploy powerful language models securely and at scale is critical for modern businesses. Enter AI21 Labs’ Jamba 1.5 Mini and NexaStack—two cutting-edge technologies that bring the power of transformer-based AI to enterprises while ensuring operational efficiency, cost-effectiveness, and data sovereignty.
This blog explores how to deploy Jamba 1.5 Mini on NexaStack, from a technical setup to real-world applications, highlighting the advantages, deployment steps, and real-time optimizations these tools offer.
What Is AI21’s Jamba 1.5 Mini?
Jamba 1.5 Mini is an advanced transformer model developed by AI21 Labs, featuring 1.5 billion parameters. It is part of the Jamba family, known for its hybrid mixture-of-experts (MoE) architecture. Jamba's design ensures that it can handle large-scale language tasks efficiently, making it ideal for enterprise workloads. It’s built to deliver high performance for tasks such as long-context document summarization, text generation, and semantic search.
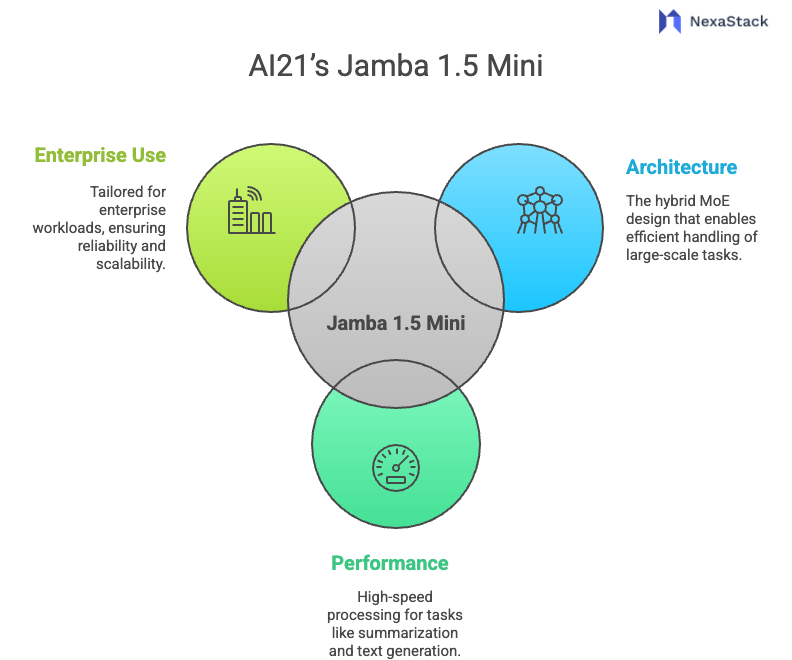 Fig 1: AI21's Jamba 1.5 Mini
Fig 1: AI21's Jamba 1.5 MiniKey Features of Jamba 1.5 Mini:
-
1.5 Billion Parameters: While not as significant as other cutting-edge models, Jamba 1.5 Mini perfectly balances computational efficiency and language understanding, making it ideal for scalable deployment on enterprise infrastructure.
-
Hybrid MoE Architecture: This architecture enables Jamba to dynamically activate different subsets of parameters depending on the task, making it resource-efficient and adaptive. It performs exceptionally well for tasks that require understanding long contexts (e.g., document review).
-
256K Context Length: With support for up to 256K tokens, Jamba 1.5 Mini can process large documents in a single pass, something that many other models with shorter context lengths cannot effectively do.
-
Open-Weight License: The model is open for commercial use with an Apache 2.0 license, allowing enterprises to deploy it within their private environments without licensing restrictions.
Jamba 1.5 Mini's flexibility and efficiency make it a prime candidate for enterprise AI deployments where resource optimization and performance are key.

Why Choose NexaStack for Jamba 1.5 Mini Deployment?
While Jamba 1.5 Mini excels in natural language processing (NLP) tasks, the real power is unlocked when paired with NexaStack, a managed platform designed to streamline AI deployment and operations. NexaStack is a fully managed LLMOps platform that supports private cloud and hybrid cloud deployment models. It gives businesses the tools they need to orchestrate, scale, and optimize large language models in a secure and governed environment.
Key Benefits of Using NexaStack:
-
End-to-End Managed AI Platform: It automates a model's entire lifecycle—from training to deployment, serving, and scaling. Enterprises can deploy Jamba 1.5 Mini with minimal setup and overhead with integrated version control, monitoring, and auto-scaling tools.
-
Flexible Deployment Models: Whether on-premises, in a private cloud, or a hybrid model, NexaStack allows you to deploy Jamba 1.5 Mini wherever your data resides. Data residency is critical for healthcare, finance, and government industries, where data compliance is mandatory.
-
Optimized for Performance: It supports GPU and CPU optimizations to ensure your deployment is cost-efficient and performance-efficient. The platform auto-scales based on demand, whether you are processing a few queries per second or thousands.
-
Security & Compliance: In an era of growing data privacy concerns, NexaStack is built with enterprise-grade security protocols, including zero-trust frameworks, RBAC (role-based access control), and end-to-end encryption. It meets the requirements of GDPR, CCPA, and other data protection regulations.
-
Seamless Model Upgrades: Upgrading models is a breeze. Whether you want to swap in newer versions of Jamba or deploy fine-tuned models, the platform ensures that your system remains agile and responsive to changes in the AI landscape.
Step-by-Step: Deploying Jamba 1.5 Mini on NexaStack
Deploying Jamba 1.5 Mini using NexaStack is a simple yet powerful process. Here’s an in-depth walkthrough of how to set up and deploy this model with NexaStack’s intuitive interface and powerful automation features.
1. Model Registration and Configuration
The first step is to register the Jamba 1.5 Mini model within NexaStack’s platform:
-
Navigate to the NexaStack Console: On the NexaStack interface, go to the Model Registry section and click on “Register Model”.
-
Search for Jamba 1.5 Mini: You can directly fetch the model from the Hugging Face Model Hub using the model name.
ai21labs/Jamba-1.5-Mini. -
Tag the Model: Add relevant metadata tags like
text-generation,long-context, andopen-weightto help classify the model. -
Automatic Configuration: Once registered, NexaStack automatically pulls the model’s weights and configuration files, making it ready for deployment.
2. Choosing the Compute Environment
NexaStack offers flexibility when choosing the computing environment for your deployment. You can select from:
-
CPU-Only: Ideal for non-latency-sensitive applications like document summarization or batch processing.
-
GPU-Accelerated: Select this option if you require high-throughput processing, such as in real-time chat applications or when scaling for large concurrent queries.
The platform automatically allocates resources, adjusting compute power to fit demand.
3. Defining the Inference Pipeline
Once the model is registered and compute resources are selected, the next step is defining how Jamba 1.5 Mini will interact with users. Using NexaStack’s PromptOps, you can create an inference pipeline:
pipeline:
name: jamba-mini-summarizer
model: ai21labs/Jamba-1.5-Mini
prompt_template: |
Please summarize the following document:
max_tokens: 512
temperature: 0.7
output_parser: json
This simple YAML definition allows you to summarize long-form text. You can easily extend this template to support question-answering, translation, or other NLP tasks.
4. Deploying and Monitoring the Model
After defining your pipeline, click Deploy. NexaStack handles all the containerization, load balancing, and auto-scaling. You can now call the model via its API endpoint, monitor real-time usage, and track performance via NexaStack’s integrated monitoring tools.
Key metrics to track include:
-
Response Time: Ensure the model returns results in real-time.
-
Request Rate: Monitor traffic to adjust scaling parameters.
-
Computer Usage: Use this data to optimize resource allocation and cost.
Applications of Jamba 1.5 Mini with NexaStack
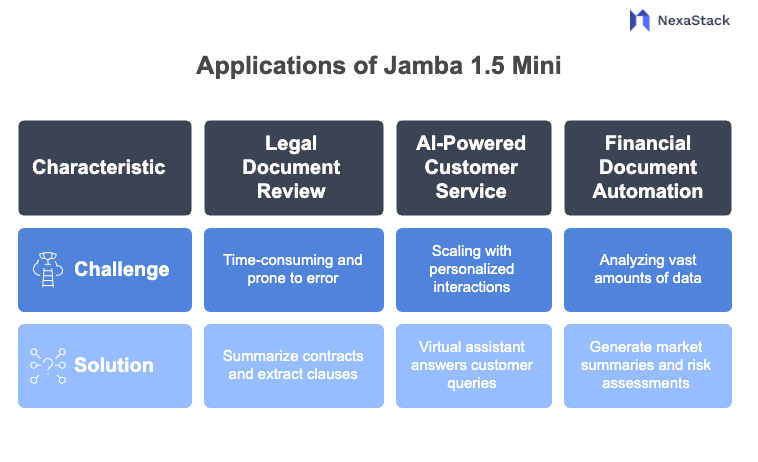 Fig 2: Application of Jamba 1.5 Mini
Fig 2: Application of Jamba 1.5 MiniThe pairing of Jamba 1.5 Mini and NexaStack is ideal for various enterprise applications that require large-scale language understanding. Here are some key examples:
1. Legal Document Review
-
Challenge: Reviewing legal contracts or compliance documents is time-consuming and prone to human error.
-
Solution: Jamba 1.5 Mini, with its long-context handling, can summarize lengthy contracts, extract key clauses, and flag critical issues, all while keeping sensitive data within a private cloud environment.
2. AI-Powered Customer Service
-
Challenge: Scaling customer support while maintaining personalized interactions.
-
Solution: Deploying Jamba 1.5 Mini as a virtual assistant can help answer customer queries over extended dialogues, ensuring that the AI can reference past interactions for context—ideal for industries like banking, telecom, and e-commerce.
3. Financial Document Automation
-
Challenge: Financial institutions often have to analyze vast amounts of data from financial reports, market data, and regulatory documents.
-
Solution: By leveraging Jamba’s ability to handle long documents, NexaStack can deploy AI models that automatically generate market summaries, financial insights, and risk assessments.
Optimizing Cost and Performance
One of Nexastack's most significant advantages is its automatic resource scaling. With AI models like Jamba 1.5 Mini, cost optimization is essential. NexaStack’s auto-scaling mechanism ensures that resources are only allocated when needed, helping to reduce idle compute costs and optimising model inference for batch and real-time queries. Additionally, GPU-optimized instances help reduce the time required for heavy computations, lowering energy consumption and cost.
Future-Proofing AI Deployments with NexaStack
The AI landscape is continuously evolving. NexaStack offers seamless model upgrades and ensures that organizations can quickly integrate newer models or fine-tuned versions of Jamba without downtime. As AI technology advances, NexaStack supports integrating multi-modal models for tasks beyond text, including vision and speech models, ensuring your deployment remains competitive and adaptable.
Conclusion: Achieving Scalable, Secure, and Cost-Effective AI
The combination of Jamba 1.5 Mini and NexaStack provides enterprises with a powerful platform for deploying private AI solutions that are both scalable and secure. Whether tackling complex legal documents, automating financial reports, or enhancing customer service, this integration offers an optimal balance between performance, cost efficiency, and security.
Using NexaStack, organizations can move from concept to production-ready AI with minimal friction and maximum control over their infrastructure. This allows them to keep their AI models up-to-date, scalable, and cost-effective.

More Ways to Explore Us
Accuracy by 40% with Precision-Driven AgentEvaluation
More Resilient Operations Securing AI with SAIF Aviator
Efficiency Gain with AutonomousOps AI


